Caching HTTP resources
This page was originally created on and last edited on .
Introduction
Web sites are, by there very nature, based on a distributed system. Your website is hosted on a web server and your visitors all connect to this from their devices which are likely far away. So some of the biggest impacts to performance involve the fact you need to make requests across the internet. This is affected by 1) latency - how long a single message takes to go to from the web browser to the web server and back - and 2) bandwidth - how much data you can download in a given period of time. Most people are used to measuring bandwidth ("my broadband is 50Mbps!"), but latency is actually a much bigger deal for typical internet browsing. If it takes 100ms to go back and forth to a website, and a website needs the average 100 resources to be loaded then at worse case that website will take a minimum of 10 seconds to load, as each resource is requested separately - and this is even if you've optimised all your images and other resources to be as small as possible. I exaggerate and it will be much less, as several connections will be made even if all resource are on the one domain, but the point still stands.
So it's really important to not just reduce the size of the resources download (by setting up gzip for example), but also to reduce the sheer number of requests. One of the best ways of doing this is by setting up caching headers. These tell the web browser how long the resource can be used for, without having to download it again, saving valuable network requests. This can be particularly helpful as users browse around your website: most pages contain a lot of the same information (e.g. logos, stylesheets, twitter icons, facebook icons...etc) and without caching these would be downloaded for each page. As well as being slow for the visitor to your site, it's also a waste of your web server resources.
Note that it is also possible to cache data in your web server, so it doesn't need to access the file system for popular resources, but this is a more advanced topic and this post does not explain that, only how to advise the web browser to cache.
How to set it up
Caching is controlled by HTTP Headers, and so are fairly easy to set up. The most difficult part is in defining your caching policy. The Apache config for this site is shown below, and other web servers could be configured similarly:
# Set some caching expiry values for performance reasons # Turn on Expires ExpiresActive On # Set up caching on media files for 1 week (60 * 60 * 24 * 7 = 604800) <filesMatch ".([iI][cC][oO]|[gG][iI][fF]|[jJ][pP][gG]|[jJ][pP][eE][gG]|[pP][nN][gG]|[fF][lL][vV]|[pP][dD][fF]|[sS][wW][fF]|[mM][oO][vV]|[mM][pP]3|[wW][mM][vV]|[pP][pP][tT])$"> ExpiresDefault A604800 Header append Cache-Control "public" </filesMatch> # Set up caching on font files for 6 months (60 * 60 * 24 * 180 = 15724800) <filesMatch ".([eE][oO][tT]|[tT][tT][fF]|[sS][vV][gG]|[Ww][Oo][Ff][Ff]|[Ww][Oo][Ff][Ff]2)$"> ExpiresDefault A15724800 Header append Cache-Control "public" </filesMatch> #Allow long term assets to be cached for 6 months (60 * 60 * 24 * 7 * 26 = 15724800) as they are versioned and should never change <Location /assets/libraries/ > ExpiresDefault A15724800 Header set Cache-Control "public" </Location> #Do not cache these files <Location /login > Header set Cache-Control "max-age=0, no-cache, no-store, must-revalidate" Header set Pragma "no-cache" </Location> # Set up caching on html/css and js files for 3 hours for html and css as they can change frequently <filesMatch ".([[hH][tT][mM]|[hH][tT][mM][lL]|[cC][sS][sS]|[jJ][sS])$"> ExpiresDefault A10800 Header append Cache-Control "public" </filesMatch>
This turns on Expires, and then sets expiries based on file type or location. So .ico files for example (with a slightly annoying syntax to make them case insensitive) can be cached by the browser for one week after access. This is is set up by setting the ExpiresDefault to A604800 which is A for access time, and 604800 seconds (60 seconds * 60 minutes * 24 hours * 7 days), and setting the Cache-Control header to public.
You can also use M instead of A to look at Modified time of the file on the server, rather than the time a visitor to your site Accessed it. So if you have a file that's replaced regularly you can say only cache that for a period of time after it was created. This allows for the caching to count down but does mean it expiries immediately after that time if the file it not updated. This is less common and most servers use Accessed time.
Similarly I set up fonts to be cached for 6 months (as they never really change), and also resources in the libraries folders to similarly be cached for a long time, and files in the /login folder to not be cached at all, using various settings.
I set .html, .css and .js files with a much shorter 3 hour time. Now most people recommend an expiry of over a week, and indeed sites like webpagetest.org and Google's PageSpeed Insights will flag resources that are not cached for at least a week, but I'm going to be a bit controversial and suggest you start with a much smaller time for HTML and CSS pages of 3 hours, for reasons given below. A lot of recommendations are also not to cache web pages (the index.html file) at all. This is because you cannot use cache busting techniques on that (as the name is not something you can change easily), but again I don't agree with this. If you are browsing round a site, and end up on the home page several times for example, then you'd want to cache this page to have instant loading. This does mean your users will potentially not see any updated content for 3 hours, which wouldn't work for a news site for example, but is fine for most other sites.
New stale-while-revalidate options
RFC 5861 proposes a stale-while-revalidate extension to the cache control headers. This allows you to set a 1 day expiry, for example, but a 7 day revalidate option, during which time it's OK to use the "stale" version. This is better than either a 1 day expiry (which is probably shorter than we would like as it would cause slowness on loading after 24 hours) and than the 7 day expiry (which is probably too long). Sounds great, but annoyingly browser support is non-existant. Chrome started implementing it but the latest commit on 1st September removed it. I really don't understand this as it seems like a great solution. More info on stale-while-revalidate.
304 - Not Modified responses
Caching should mean that your browser should not bother requesting the resource until the expiry time has passed, which saves the network request as intended. However there are two other scenarios that also could benefit from caching by reducing download times, though still making network requests:
- If the expiry time has passed, but the resource has not been cleared out of the web browser cache, then the next time the browser visits that page it will send a message to the web server with a "If-Modified-Since" header. This tells the browser to only send the file if it's newer than the last time it got it.
- The same will happen if a user refreshes a page by pressing the refresh button, or by pressing F5 before the cache expiry has happened.
In both case the web server should respond with a 304 code meaning the file has not been modified since then, instead of sending the full file. The web browser then just re-uses the cached version and also marks it as valid for the same amount of time again as if it had downloaded the file. This saves download (bandwidth) though you still suffer from from the latency of sending the request in, and getting the 304 response back.
ETags are another way of supporting 304 requests, however they have quite a few problems so I recommend turning them off (though not for the old reason people used to recommend turning them off - see my post on ETags for more information on this).
There is also a new Cache-Control: immutable header being implemented by Firefox, which can prevent a 304 for even being attempted for resources which will never change. This looks interesting and hopefully other browsers will implement it too.
How to check whether caching is working or now
Most browsers allow you to use Developer Tools (often accessed with F12) to see cache control information in the Network tab. For example below shows two screenshot of Chrome's Network tab when loading this page, in the first when it's cached, and in the second with a reload where some items returned a 304:
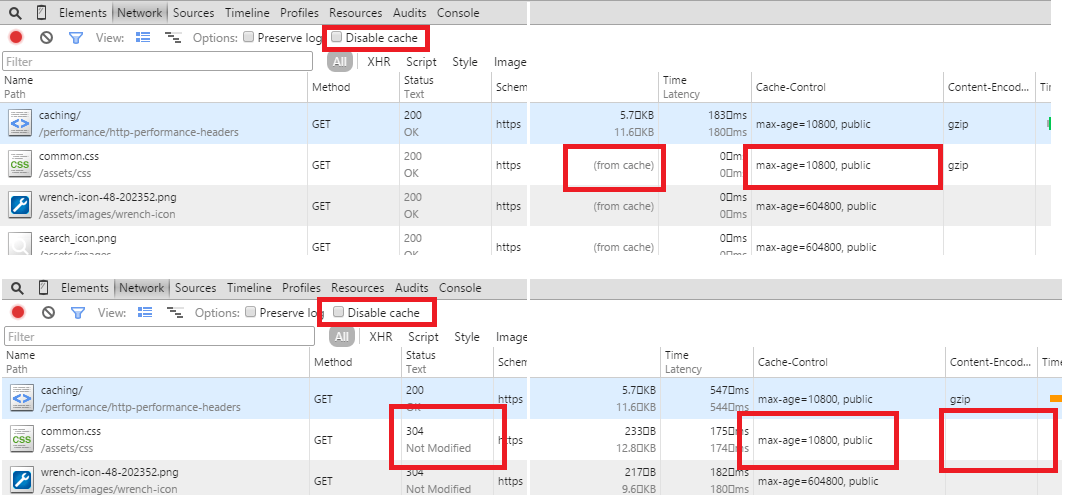
An important note is to remember to turn off the Disable cache option when testing caching. Normally when in developer tools you don't want caching as you are probably developing, so the default is to turn caching off, which can be confusing when testing caching! Another point to note is that the 304 response is a new response, so isn't delivered over gzip for example, so if using developer tools to test gzip it's easy to be confused why your resources are not being gzipped (they probably are, but a 304 response doesn't actually send the resource back so does not need gzipping).
Support
Support is pretty universal with all major web browsers and web servers supporting caching since it is part of the HTTP/1.1 standard.
The Downsides
The main down side is when you want to change your website. If you spot a mistake, or want to publish new content, but someone has cached your web page then they will not see your updates when they revisit, until the cache expires. This is the reason I've gone with a three hour expiry for resources that might change above. three hours means the resources will be cached for visitors who browse around your site (unless your website is so interesting that they are on there for longer than that!), so at most the content will be three hours old. This is a fairly simple set-up and does not require much maintenance or changes to how you run your website, but doesn't make the best use of the cache and does mean people will re-download content when they possible do not need to (e.g. when visiting the next day). If the content is still in the cache they may be lucky and get a 304 request but even that costs time to send across the network
Cache-Busting
The ideal way is to have long cache expiries, and force the browser to download the content if it changes. There are various tricks to do this, but most involve changing the filename (so the browser thinks it's new file different than the one it has in it's cache). css-tricks.com has an excellent page on some of the methods of doing this, but these methods require a bit of extra effort or a robust build process for your website to update the version number everywhere it needs to be updated. They also don't address the default file page (often called index.html).
Personally I think the three hour expiry, is an easier way to handle this issue so you don't need to cache-bust at all. Yes it does mean that the first return visit to your website will likely be slower than you would like, and that first load can be very important to give a good initial impression, but this policy is easier for most people to implement and requires little extra thought. I would rather people did that (so browsing around the site is quick), than have no caching at all. This does leave you open to displaying old content for up to three hours (which personally I don't think it as problem for most sites) and also means that any CSS changes for example, could break pages for three hours (which is a bigger problem I admit, though most people will just refresh if the page looks funny, and hopefully you will not make many breaking changes like this). Another downside of this, is that if you run any performance tools like webpagetest.org and Google's PageSpeed Insights then they will flag this to you, even though you have made a conscious decision to have a "short expiry". A proper caching policy with cache busting when you need it is better, so if you can implement that then do, but if not then this three hour policy idea may work for you.
Summary
Caching is a great way to speed up your website and by setting a relatively short expiry on your key assets that are liable to change, this can be implemented easily with little or no change to how you run your website after the initial set up. For sites that need to be able to update content quickly, caching may require more thought (or to be turned off completely for some pages like "breaking news"), and some of the tricks necessary to allow you to "bust" the users cache, but even though it's usually possible to cache at least some of the resources that make up your website.
Want to read more?
More resources on caching
- The RFC for HTTP/1.1 which also defines cache control headers.
- Apache guide to caching.
This page was originally created on and last edited on .
Tweet