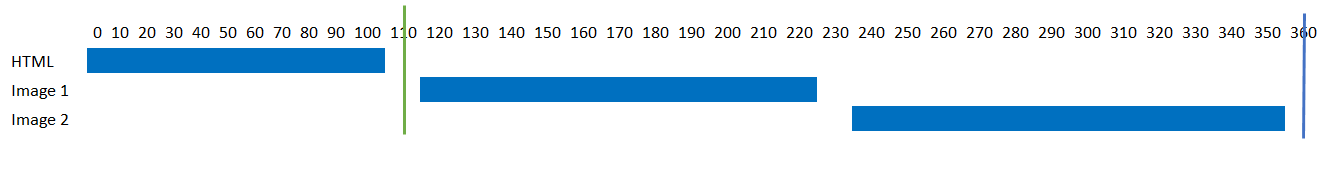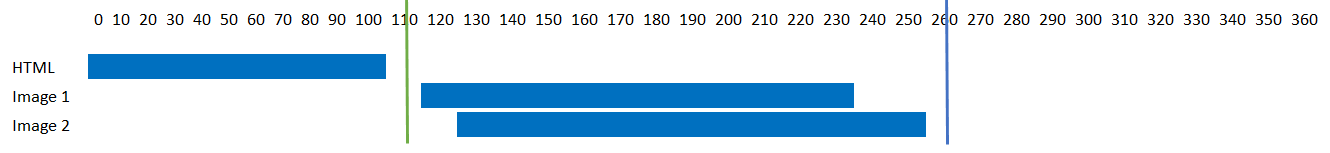This page was originally created on and last edited on .
Why do we need HTTP/2? - an excerpt from "HTTP/2 in Action"
By Barry Pollard
Why do we need HTTP/2? The web works fine under HTTP/1.1 doesn’t it? In this article, we’ll tackle these questions with a well-known, real-world example and show why HTTP/1.1 has fundamental performance problems, and therefore why HTTP/2, is needed now.
HTTP/1.1 is what most of the internet is built upon, at the time of writing, and it’s functioning reasonably well for a 20-year-old technology. However, during that time, web usage has exploded, and we’ve moved from simple static web sites to fully interactive web applications for online banking, shopping, booking holidays, watching media, socializing and almost every other aspect of our lives.
Internet availability and speed is increasing with technologies like Broadband and Fiber for our offices and homes, which means speeds are many times better than the old dial-up speeds users had to deal with when the Internet was first launched. Even mobile has seen technologies like 3G and 4G bring broadband level speeds on the move at reasonable, consumer-level prices.
Although the increase in download speeds has been impressive, the need for faster speeds has outpaced this. And although broadband speeds will probably continue to increase for some time yet, there are also certain fundamental limitations to other aspects that impact internet speed that can’t be fixed as easily. As we shall see, latency is a key factor in browsing the web and it’s fundamentally limited by the speed of light – a universal constant that physics says we can’t increase.
HTTP is a request and response protocol that was originally designed for requesting a single plain text content, which ended the connection upon completion. HTTP/1.0 introduced other media types, like allowing images on a web page, and HTTP/1.1 ensured the connection wasn’t closed by default, on the assumption that more requests would likely be needed by the web page.
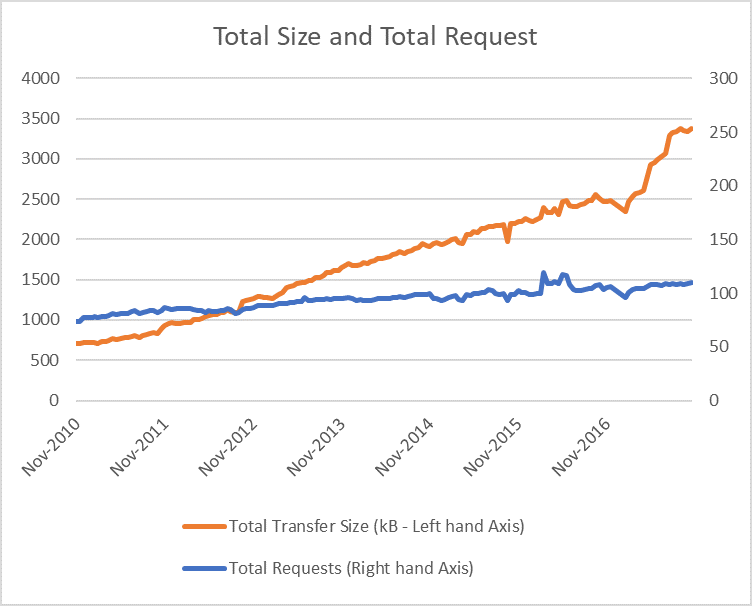
These were good improvements, but the Internet has also changed considerably since the last revision of HTTP (HTTP/1.1 in 1997, though the formal spec was clarified a few times, the last in 2014). The HTTP Archive runs a trends site at http://httparchive.org/trends.php which allows you to see the growth of web sites as shown in Figure 1 for the last five years:
As can be seen, the average website requests over 110 resources, and weighs in at a hefty 3.3Mb in size. A wide variation leads to that average though. Looking at the Alexa Top 10 websites in the US, for example, we see the results shown in Table 1.
Table 1 Top 10 websites in United States and size
Site
Number of Requests
Size
https://www.google.com
17
0.4Mb
https://www.youtube.com
75
1.6Mb
https://www.facebook.com
172
2.2Mb
https://www.reddit.com
102
1.0Mb
https://www.amazon.com
136
4.46Mb
https://www.yahoo.com
240
3.8Mb
https://www.wikipedia.org
7
0.06Mb
https://www.twitter.com
117
4.2Mb
https://www.ebay.com
160
1.5Mb
https://www.netflix.com
44
1.1Mb
The table shows that some websites (e.g. Wikipedia, Google) are hugely optimized and require few resources, but others load hundreds of resources and many megabytes of data.
The growth of websites is primarily driven by becoming more media-rich, with images and videos being the norm on most websites. Websites are also becoming more complex with multiple frameworks and dependencies needed to correctly display their content.
Websites are also less likely to be simple, single-load pages. Web pages started out as static pages, but as the web became more interactive, web pages started to be generated dynamically on the server side - think CGI (Common Gateway Interface) pages or Java Servlet or JSPs (Java Server Pages). The next stage moved from generating full pages server-side to having a basic HTML page, which is supplemented by AJAX (“asynchronous JavaScript and XML”) calls made from client-side JavaScript. These AJAX calls make extra requests to the web server to allow the contents of the web page to change, without necessitating a full page reload. The simplest way of understanding this is by looking at the change in web searches. In the early days of the web, before the advent of search engines, directories of websites and pages were the primary way of finding information on the web (static and updated occasionally). Then the first search engines arrived, which allowed submitting a search form and getting the results back from the server (dynamic pages generated server-side), yet nowadays most search sites make suggestions in a drop down as you type – before you even click search. Google even went one step further and used to show results as you typed, though they’ve reversed this in summer of 2017 as more searches moved to mobile, where this made little sense.
It’s not only search engines - all sorts of web pages make heavy use of AJAX requests, from social media sites which load new posts, to news websites which update their home page as new news comes in.
All this extra media and AJAX requests allow the websites we use to be more interesting web applications. However, the HTTP protocol wasn’t designed with this huge increase in resources in mind, and the protocol has some fundamental performance problems in its simple design.
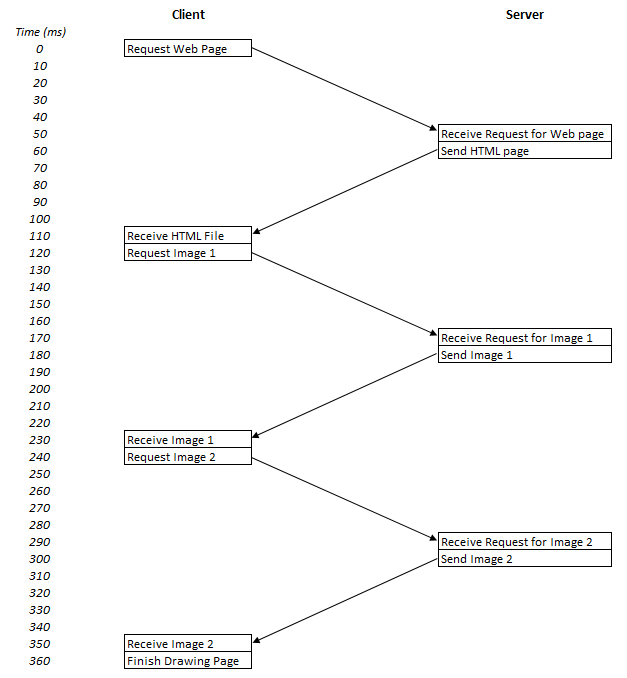
Let’s illustrate this with an example. Let’s say we have a simple webpage with some text and two images. Let’s say the request takes 50 milliseconds (ms) to travel across the Internet to the web server, and that this is a static website, so the webserver just picks the file up from the fileserver and sends it back, and let’s assume it can do this in 10ms. Similarly, the web-browser takes 10ms to process the image and send the next request. These figures are all hypotheticals. If you have a Content Management System (CMS) that creates pages on the fly (e.g. WordPress runs PHP to process a page), then the 10ms server time may not be accurate depending on exactly what processing is happening on the server and/or database. Additionally, images may be large and take longer to send than a request, but these are for illustration purposes – we’ll look at real examples later in the article. Anyway, for this simple example, the flow under HTTP would look like this Figure 2.
Figure 2 Request-Response flow over HTTP for a basic example website.
The boxes represent processing at either the client or server end, and the arrows represent network traffic. What’s immediately apparent in this hypothetical example, is how much time is spent sending messages back and forth. Of the 360ms needed to draw the complete page, only 60ms was spent processing the requests at either the client side or the browser side. 300ms, or over 80% of the time, was spent waiting for messages to travel across the internet. During this time, neither the web browser nor the web server are doing much in this example - this is wasted time and it’s a major problem of the HTTP protocol. At the 120ms mark, after the browser asks for image 1, it knows it needs image 2, but it waits around for the connection to be free, until it can send the request for it – which doesn’t happen until the 240ms mark. This is inefficient, but there are ways around this, as we shall see later (e.g. most browsers open multiple connections for example), but the point is that the basic HTTP protocol is quite inefficient.
Most websites aren’t made up of only two images and the performance issues shown above increase with the number of assets that need to be downloaded. This is particularly true for smaller assets where the processing on either side is small, relative to the network request and response time.
One of the biggest problems of the modern internet is due to latency, rather than bandwidth. Latency measures how long it takes to send a single message to the server, whereas bandwidth measures how much you can download. Newer technologies are increasing bandwidth all the time (which helps address the increase in size of websites), but latency isn’t improving (which therefore limits the number of requests from increasing). This is because latency is fundamentally restricted by physics (the speed of light) and, believe it or not, data travelling through fiber optic cables are pretty close to travelling at the speed of light already; there’s only a little to be gained here no matter how much the technology improves.
Mike Belshe of Google did some experiments, which show we’re reaching the point of diminishing returns for increasing bandwidth. We may now be able to stream high definition television, but our web surfing hasn’t got faster at the same rate and often takes several seconds to load even on a fast internet connection. The Internet can’t continue to increase at the rate it has unless we solve the fundamental performance issues of HTTP/1.1 - that too much time is wasted in sending and receiving even small HTTP messages.
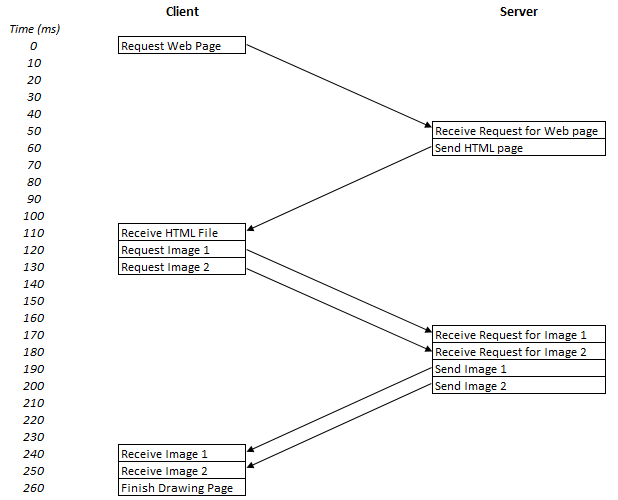
HTTP/1.1 tried to introduce the concept of pipelining which allowed concurrent requests to be sent, before responses were received. This would allow requests to be sent in parallel. The initial HTML still needs to be requested separately, but once the browser saw it needed two images and it could request them both one after the other. This is shown in Figure 3, and it shaves off 100ms – or a third of the time in this simple, hypothetical example.
Figure 3 HTTP with pipelining for a basic example website.
Pipelining should’ve brought huge improvements to HTTP performance but, for a number of reasons, it was difficult to implement, easy to break, and not well supported on either web browser or web server sides. The result is that it’s rarely used – none of the main web browsers use it, for example.
Even if pipelining was better supported, it still required responses to be returned in the order they were requested. For example, if Image 2 was available, but Image 1 needed to be fetched from another server, then the Image 2 response waited – even though it should be possible to send this file immediately. This is known as the head-of-line blocking (HOL blocking) problem and it’s common in other networking protocols as well as HTTP.
The flow of requests and responses as shown in Figures 1 and 2 are often shown as waterfall diagrams with the assets listed on the left and time increasing on the right, as these are easier to read than the above methods for large numbers of resources. Figure 4 shows a waterfall diagram for our example site, and Figure 5 shows the same when pipelining is used.
Figure 4 Waterfall diagram of Example websiteFigure 5 Waterfall diagram of Example website with pipelining.
In both examples, the vertical green line represents when the initial page can be drawn (known as first paint time), as images are often loaded after the initial paint time, and the vertical blue line shows when the page is finished. These examples are simple, but they quickly get quite complex when we show some real-life examples later.
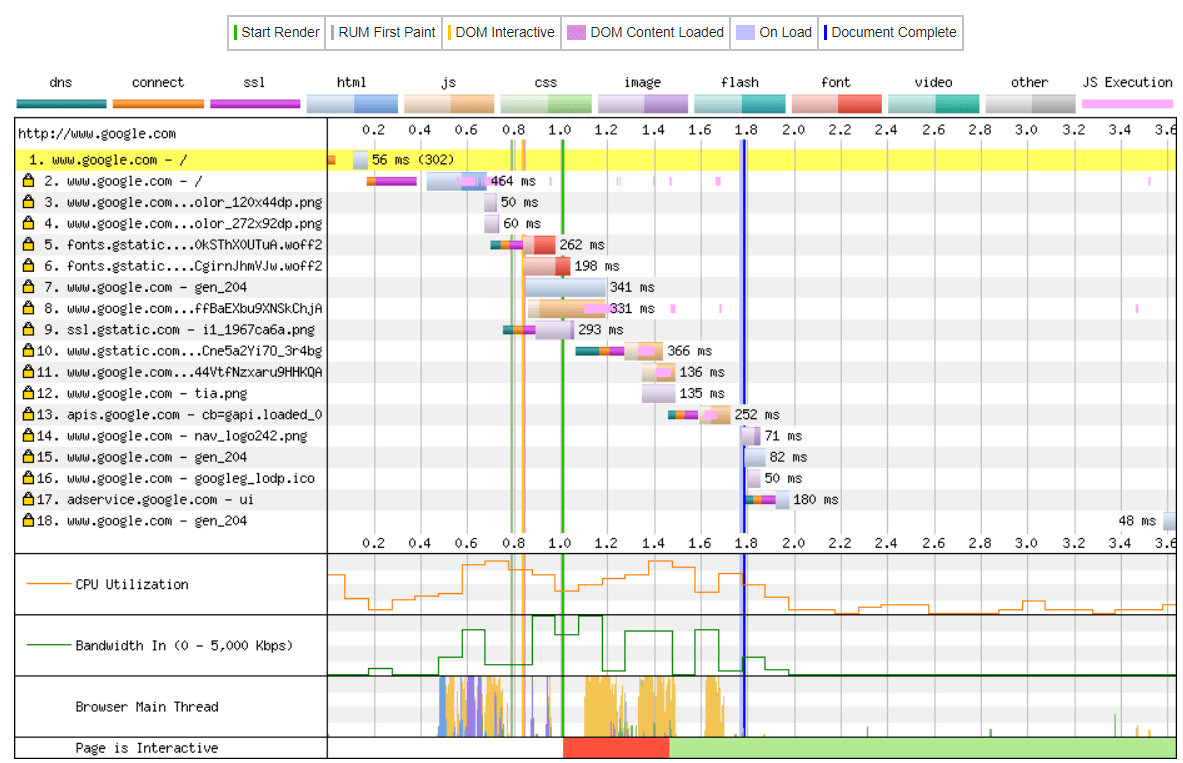
Various tools including www.webpagetest.org and web browser Developer Tools, generate waterfall diagrams and these are important to understand when reviewing web performance. Most of these tools also break the total time for each asset into the various components such as DNS lookup, TCP connection time…etc. as show in Figure 6.
This gives a lot more information than my simple waterfall diagrams - it breaks each request into several parts including:
The DNS lookup (teal color)
The network connection time (orange color)
The HTTPS negotiation time (purple color)
The resources request and response – where it even gives a different color depending on the resource time (HTML resources are in blue, fonts in red…etc.). It also splits the resource load into two pieces with the lighter color for the request and the darker color for the response download.
It includes various vertical lines for the various stages in loading the page.
Finally, at the bottom it gives a number of other graphs to show usage of the CPU, the network bandwidth and what the browser’s main thread is working on.
All of this is useful information when analyzing the performance of a website and we’ll make heavy use of waterfall diagrams to explain these concepts.
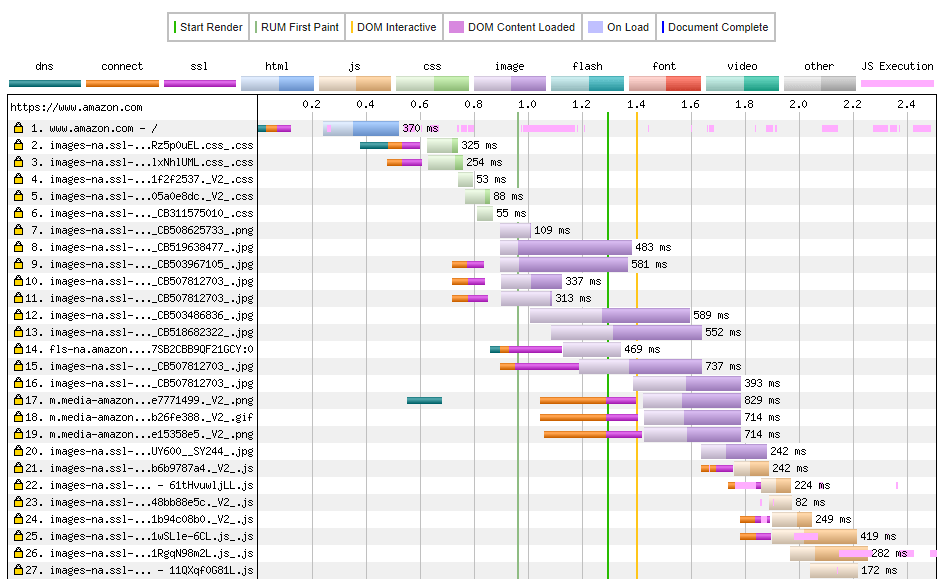
We’ve talked theoretically up until now, but let’s now look at a real-world example. If we take www.amazon.com as a well-known website, and run it through www.webpagetest.org we get the following waterfall diagram shown in Figure 7. This diagram demonstrates many of the problems with HTTP/1.1, and I’ll explain it in detail.
The first request is for the home page, which I’ve repeated in a larger format in figure 8:
Figure 8 The first request for the home page
It requires time to do a DNS lookup (dark blue or teal color), time to connect (orange), and time to do the SSL/TLS HTTPS negotiation (purple). This is before a single request is sent. The time is small (slightly over 0.1 seconds in above example), but it adds up. Not much can be done about that for this first request - this is part and parcel of the web, and although improvements to HTTPS ciphers and protocols might reduce the purple time, the first request is going to be subject to these delays. The best you can do here is ensure that your servers are responsive and, ideally, close to the users to keep round trip times as low as possible.
After this initial set up, there’s a slight pause – which I can’t explain; it could be due to slightly inaccurate timings or an issue in the Chrome browser (I didn’t see the same gap when repeating the test using Firefox). Then the first HTTP request is made (in light blue), and the HTML is downloaded (slightly darker blue), parsed and processed by the web browser.
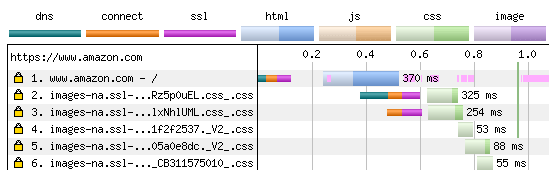
The HTML makes references to several CSS files, which are also then downloaded as shown in Figure 9:
Figure 9 The 5 requests for the CSS files
These CSS files are hosted on another domain (https://images-na.ssl-images-amazon.com), which has been sharded from the main domain for performance reasons. As this is a separate domain, we need to start over from the beginning for the second request and do another DNS lookup, another network connection and another HTTPS negotiation before we can use this domain and download the CSS. Although the setup time for request 1 is somewhat unsolvable, this second setup time is wasted – the domain name sharding is done to work around HTTP/1.1 performance issues. Note also that this CSS file is seen early on in the processing of the HTML page in request 1, causing request 2 to start slightly before the 0.4 second mark despite the fact the HTML page doesn’t finish downloading until after 0.5 seconds. The browser hasn’t waited until the full HTML page has been downloaded and processed, but instead requested the CSS file as soon as it’s seen the CSS file referenced.
The third request is for another CSS file on the same sharded domain. As HTTP/1.1 only allows a single request in flight at the same time, the browser creates another connection. We don’t need the DNS lookup this time (as we know the IP address for that domain from request 2), but we do need the costly TCP/IP connection setup and HTTPS negotiating time before we can request this CSS. Again, this is to work around HTTP/1.1 performance issues.
After this it requests three more CSS files which are loaded over the two connections we’ve already established. Not shown above is why it didn’t request these other CSS files immediately – which would necessitate creating even more connections and the cost associated with them. I’ve looked at the Amazon source code and there’s a <script> tag before these CSS requests which blocks those requests and explains this. This is an important point: although HTTP/1.1 inefficiencies are a problem for the web and could be solved by improvements to HTTP (like those in HTTP/2), they’re far from the only reasons for slow performance on the web.
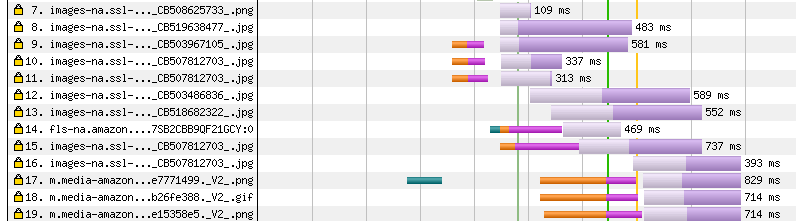
Once the CSS has been dealt with in requests 2 through 6, the browser decides the images are next and starts downloading these as shown in Figure 10.
Figure 10 Image down loads
The first .png file is in request 7 – which is a sprite file of multiple images when I looked at it (not shown above), and another performance tweak that Amazon implemented. After that some .jpg files are downloaded from request 8 onwards.
Once two of these images requests are in flight, the browser needs to make more costly connections to allow other files to load in parallel in requests 9, 10 and 11, and then again for requests 14, 15, 17, 18 and 19.
In some cases (request 9, 10 and 11), it looks like the browser has guessed more connections will likely be needed and set up the connections in advance, which is why the orange (Connect) and purple (SSL) parts happen earlier and why it can request the images at the same time as requests 7 and 8.
Amazon has also added a performance optimization to do a DNS prefetch for the m.media-amazon.com well before it needs it, though oddly not for fls-na.amazon.com. This is why the DNS look up for request 17 happens earlier at the 0.6 second mark and well before it’s needed.
The loading continues on past these requests, but even only looking at these first few requests has already identified problems with HTTP/1.1, and I’ll not belabor the point by continuing through the whole-site load.
Many connections are needed to avoid any queuing and often the time taken to make this connection doubles the time needed to download the asset. Web Page Test has a handy connection view which is shown in Figure 11 for this same example.
Here it can be seen that loading Amazon requires 20 connections for the main site - ignoring the advertising resources which add another 28 connections not shown in above screenshot. Although the first six images-na.ssl-images-amazon.com connections are fairly well used (connections 3-8), the other four connections for this domain (connections 9-12) are less well used and, like many other connections (e.g. 15, 16, 17, 18, 19, 20), are used to load only one or two resources, making the time to create that connection wasteful.
The reason these four extra connections are opened for images-na.ssl-images-amazon.com (and why Chrome appears to break its limit of six connections per domain) is interesting and took a bit of investigation. Requests can be sent with credentials (which usually means cookies), but requests can also be sent without, which are handled by Chrome using separate connections. For reasons that I admit I don’t understand, Amazon chose to use setAttribute("crossorigin","anonymous") in the JavaScript requests – without credentials - which means the existing connections aren’t used and instead more connections are created. To be honest I can’t see any reason for this, because they allow credentialed connections for the images and I couldn’t see any cookies on the images-na.ssl-images-amazon.com domain. Regardless, they explicitly do this, and the above shows this is inefficient at a HTTP level, though they may have other reasons for this (e.g. security).
The Amazon example shows that even when a site is well-optimized with the workarounds necessary to boost performance under HTTP/1.1, there’s a still a performance penalty to using these performance workarounds. These performance workarounds are also complicated to set up. Not every site wants to manage multiple domains, or sprite images together, or merge all their JavaScript (or CSS) into the one file, and not every site has the resources of Amazon to create these optimizations - or are even aware of them. Smaller sites are often much less optimized and therefore suffer the limitations of HTTP/1 even more.
Hence the need to adopt HTTP/2! We’re going to stop here. If you’re interested in learning more about HTTP/2, read the entire first chapter of HTTP/2 in Action for free here and see this slide deck.